















商品详情优化
优化思路
在电商网站中,用户在购买一件商品之前,往往会多次浏览商品详情页,所以商品详情页的访问量通常是比较大的,所以我们需要优化商品详情页的性能。这里的性能优化,主要针对数据库的访问,因为限制系统性能的瓶颈的,往往是数据库的IO操作。
所以,我们的优化思路就是,通过引入缓存,来减少对于数据库的访问,同时为了加快对于缓存数据的访问,我们可以采用内存数据库Redis来存储缓存数据。
在引入基于Redis实现的缓存之后,对于后端数据的访问过程如下:
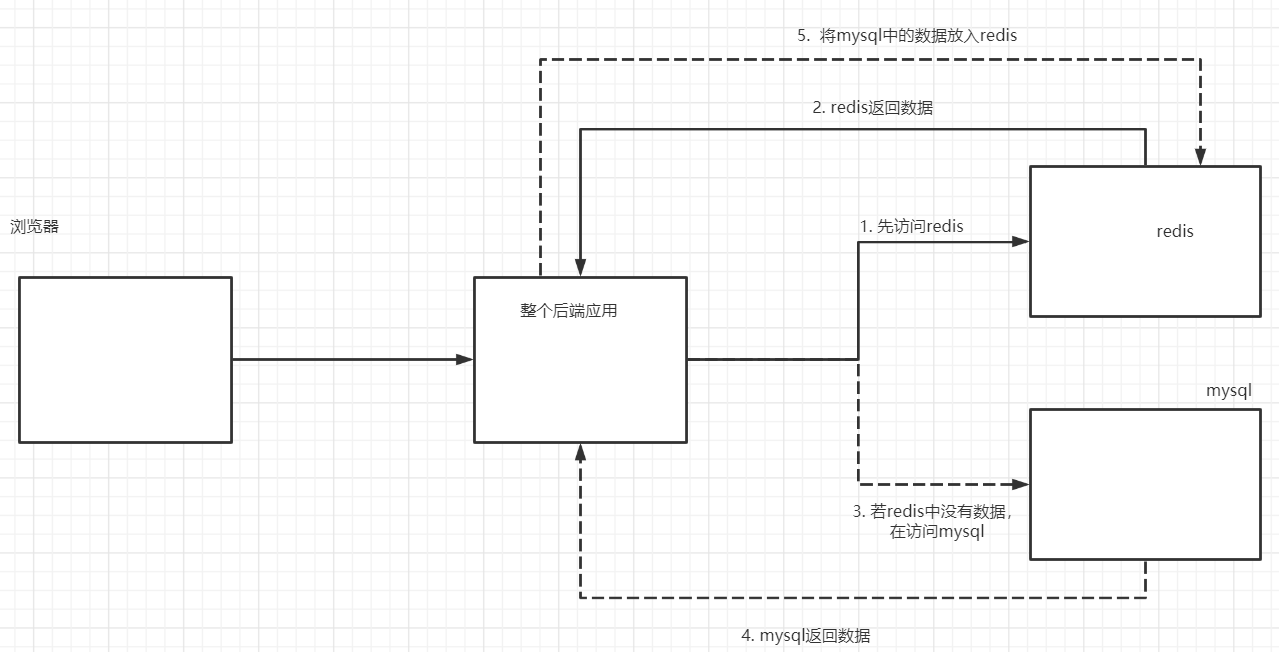
缓存问题分析
但是,我们如果一旦使用了Redis缓存,随之而来,就会引出三个问题:
- 缓存穿透
- 缓存雪崩
- 缓存击穿
下面,我们就分别分析以上三个问题出现的场景及其解决方案。
缓存穿透
缓存穿透是指查询数据库中不存在的数据。由于数据库中不存在,所以缓存中自然也不存在,这将导致这个不存在的数据每次请求都要到数据库中去查询。如果查询这种不存在的数据的请求量很大(比如受到了攻击),很容易就可能导致数据库宕机。
针对缓存穿透问题的解决方案是,针对这种数据库中查询不到结果的请求,将其结果定义为null或者其他的默认值,缓存在redis中,并给该缓存结果定义一个过期时间(最长不超过5分钟)。
缓存雪崩
缓存雪崩是指,在redis中具有过期时间的数据在同一时刻失效,导致大量的请求(就像雪崩一样)同时访问数据库,导致数据库的瞬时压力过大甚至宕机
针对缓存雪崩问题的解决方案是,在redis中给所有具有过期时间的数据,在设置过期时间时增加一个随机值,比如1-5分钟,这样每一个缓存数据的过期时间相同的概率就会降低,就很难引发集体失效的事件。
缓存击穿
缓存击穿是指,针对单个具有过期时间的热点key数据,被高并发的请求访问的情况,如果这个热点key数据过期时间到,就会导致,针对这个热点key数据的高并发请求都访问数据库。
这里需要注意下,缓存击穿针对的是单个热点key失效的情况,而缓存雪崩针对的是大量key失效的情况。
针对缓存击穿的解决方案是,通过加锁来解决
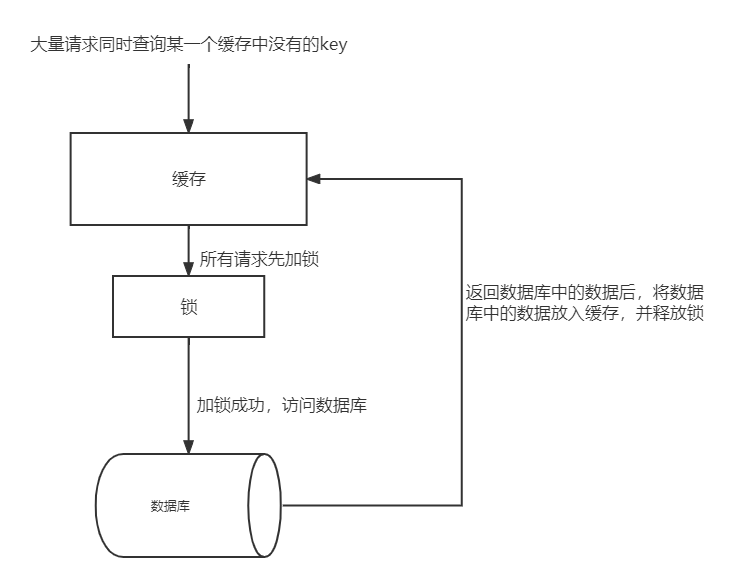
压测工具
为了能够模拟高并发场景,我们先来介绍一个压测工具jmeter。
Apache Jmeter是Apache组织的一个开源项目,是一个100%纯java桌面应用,它可以为目标应用模拟巨大的负载量,用以测试性能。它是一个多线程工具,允许多个线程并发取样,并支持多种不同的协议比如,HTTP,JDBC,TCP等等,可以用于多种不同的领域。
把压缩包解压之后,进入bin目录,windows操作系统双击jmeter.bat即可运行,类unix操作系统执行 sh ./jmeter.sh即可执行
启动之后我们可以,调整界面为简体中文
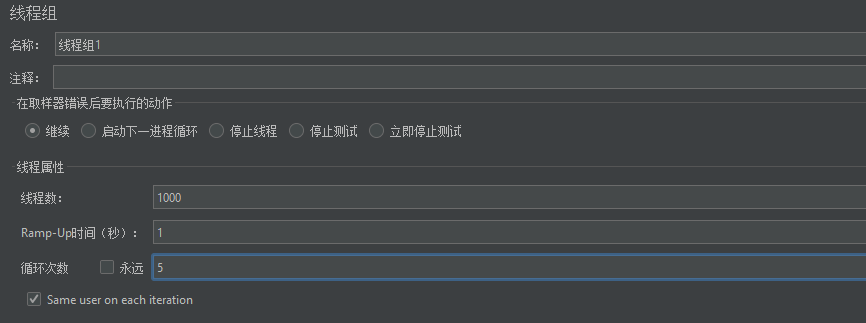
要发起测试,首先必须先创建一个线程组(可以理解为一个线程池),有了这个线程组,我们就可以通过该线程组中的多个线程模拟并发请求。
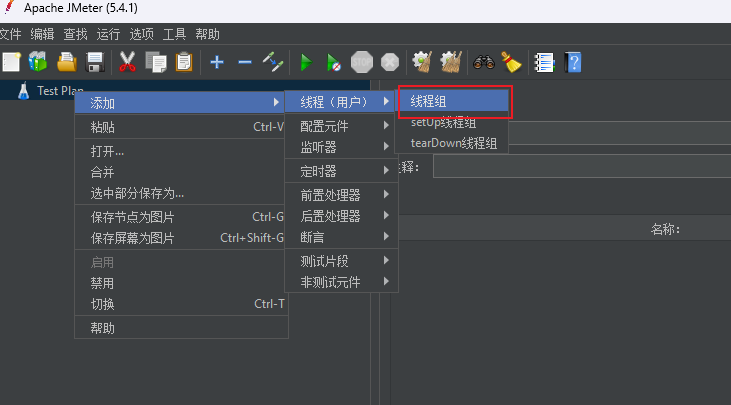
同时,我们还可以自定义,线程组中的线程数,多个线程启动的时间,以及每个线程发起多少次请求
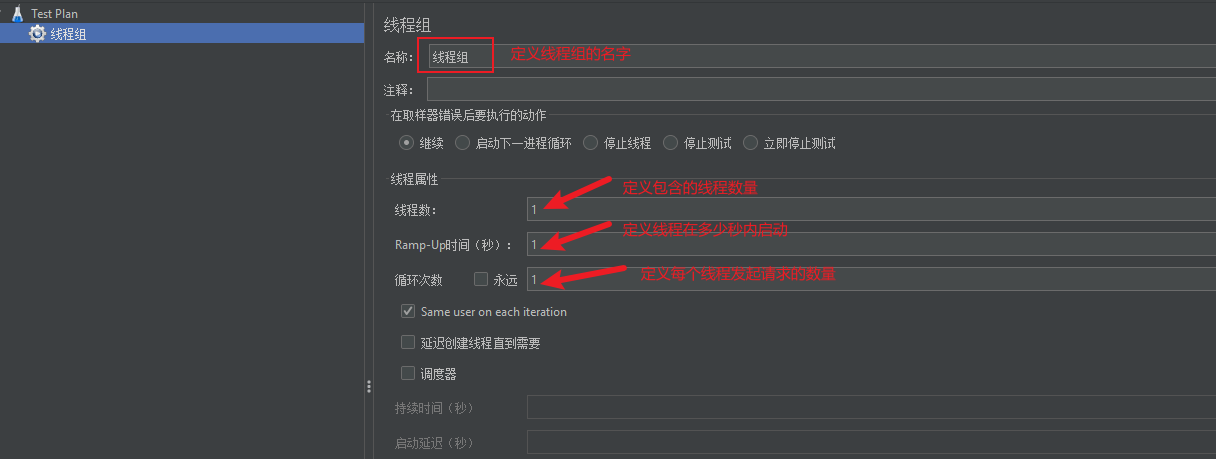
接着,我们可以在线程组中定义要发起的请求
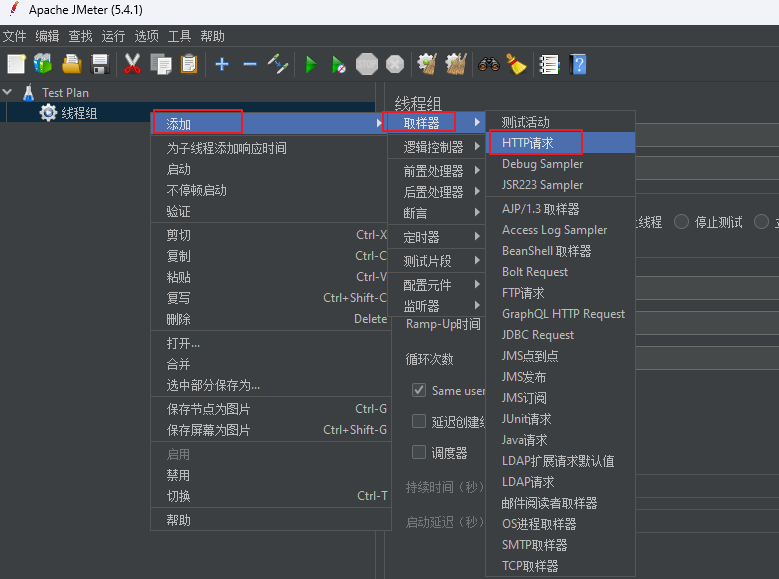
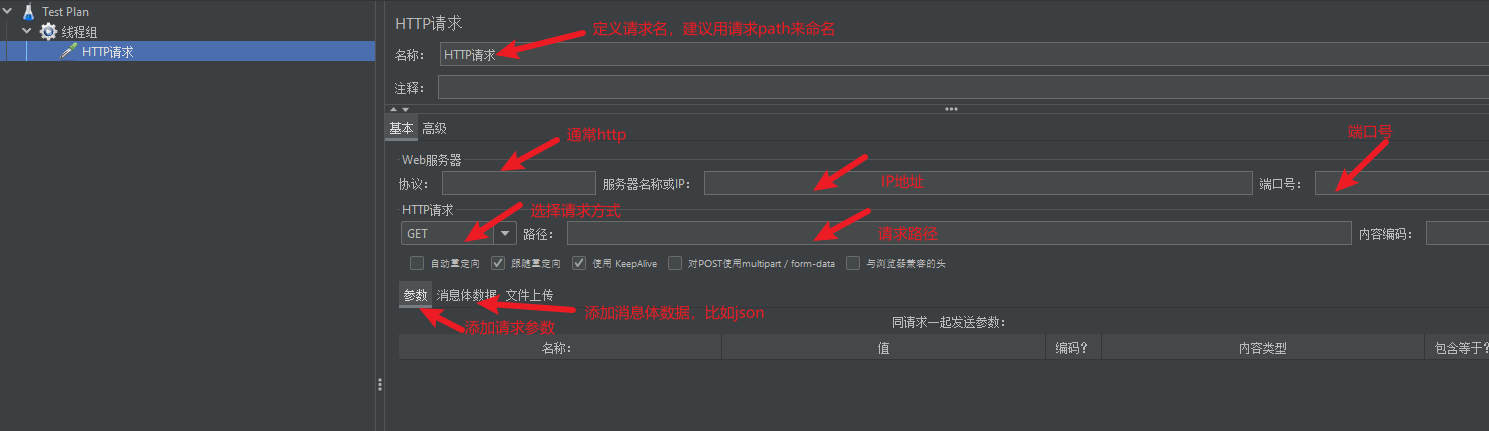
在添加完请求之后,如果我们想看到请求结果,我们还需要添加查看结果树,和聚合报告。
添加完查看结果树和聚合报告之后,我们就可以在线程组中执行请求了
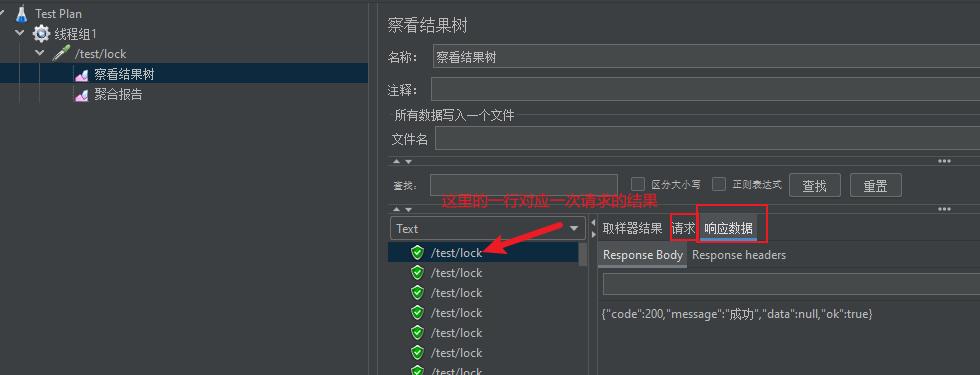
在查看结果树中,我们可以看到所发的几乎每一次请求对应的请求和响应
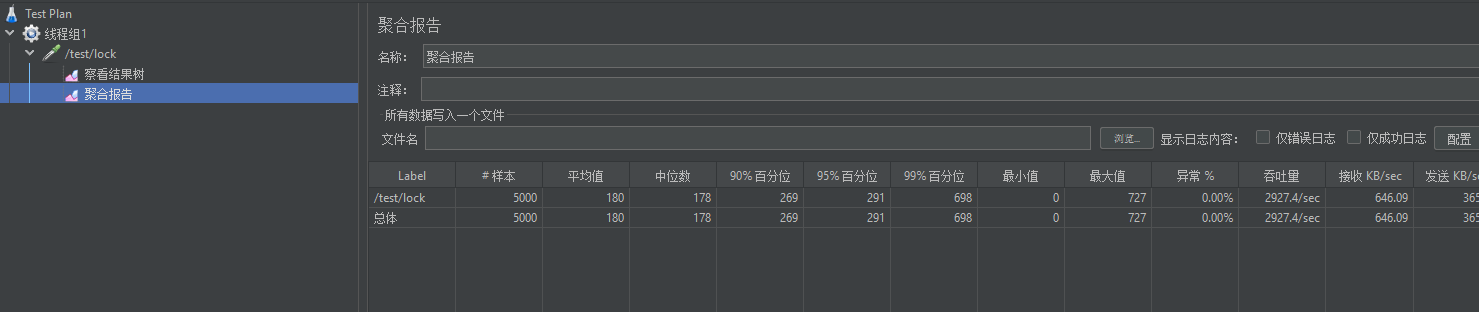
在聚合报告中,我们可以看到,对于多次请求的统计数据,通过聚合报告中的统计数据,我们可以评估接口性能
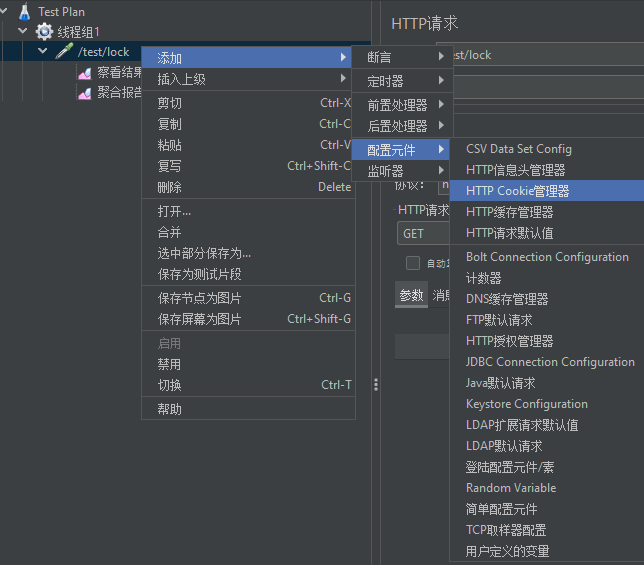
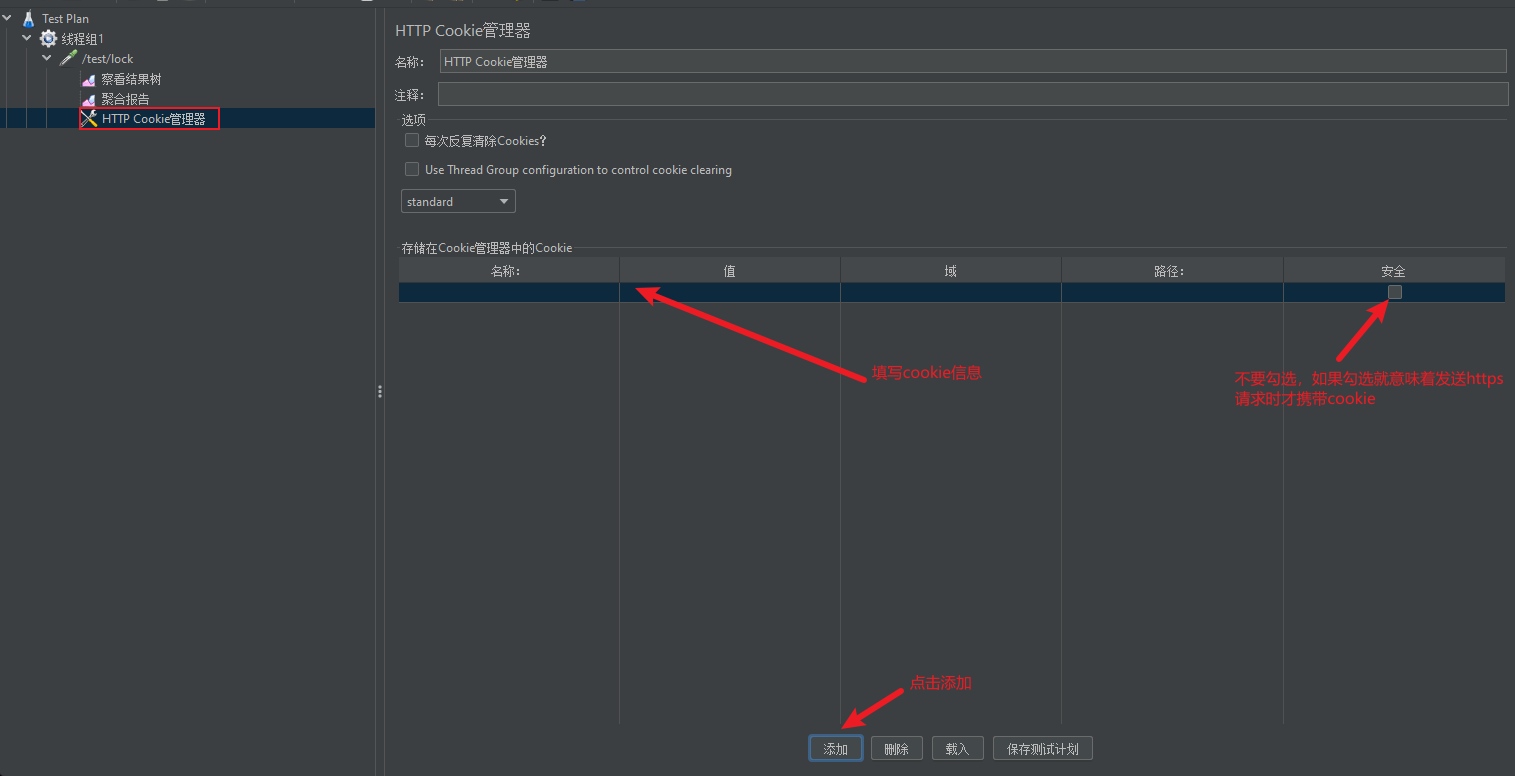
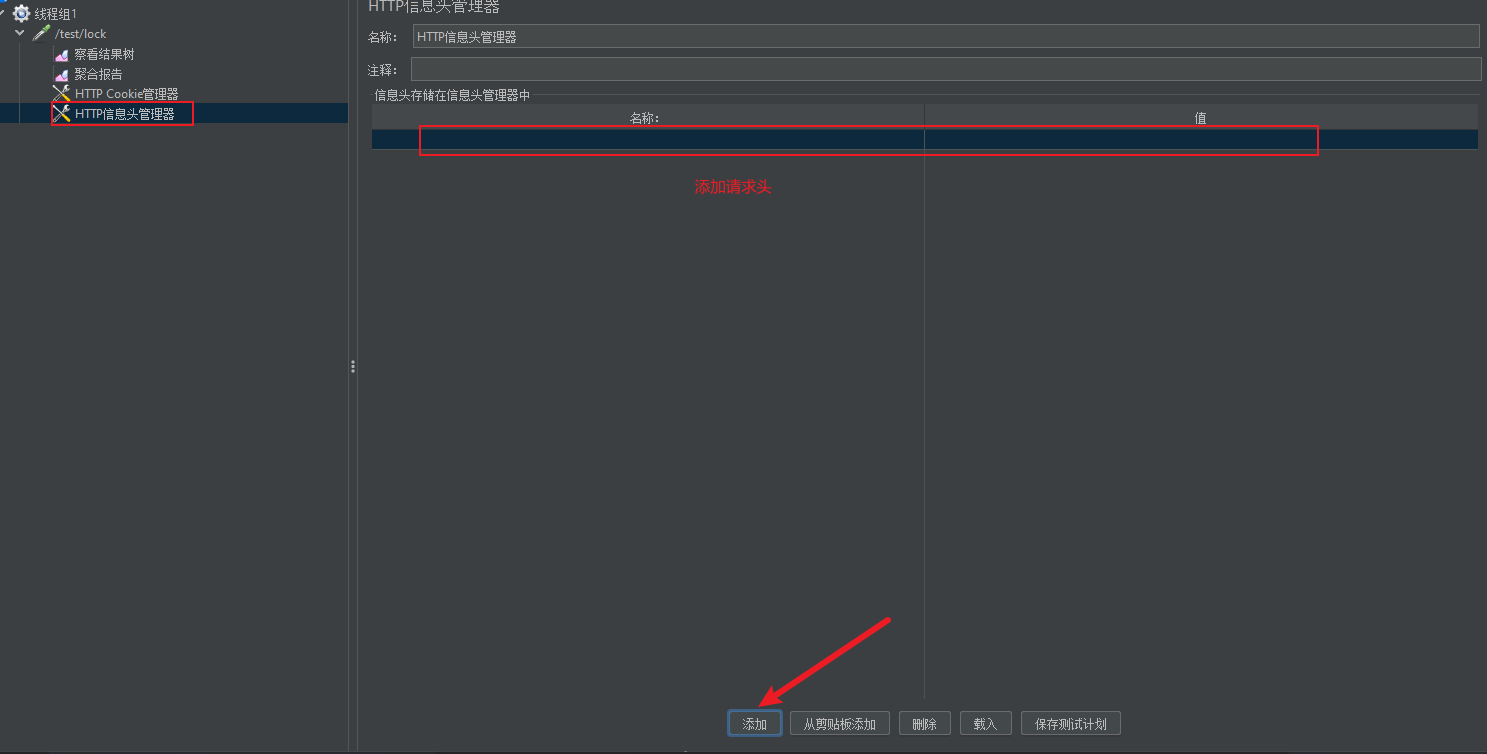
如果在请求中,我们需要添加cookie,那我们需要添加HTTP Cookie管理器
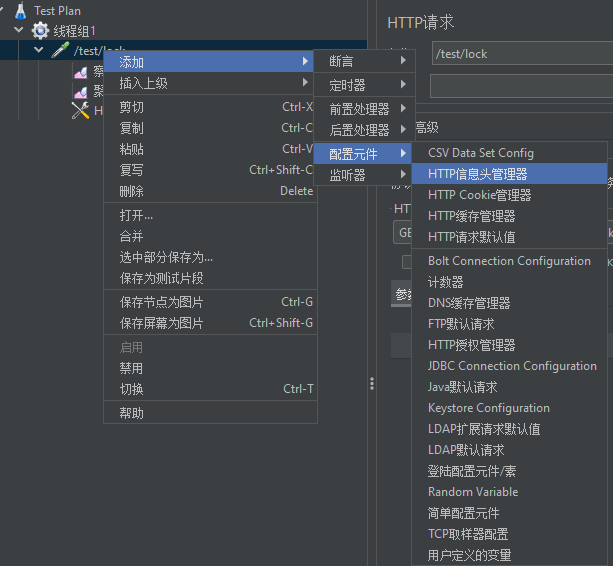
有时,我们再发起请求时,还需要添加请求头,比如发送json,需要添加ContentType: application/json,此时我们可以通过HTTP 信息头管理器来添加
锁
本地锁
测试单个服务实例
继续上面的问题,为了避免发生缓存击穿的问题,所以需要访问数据库之前需要加锁,加的是什么样的锁呢?我们先使用synchronized锁对象。
在product-service中定义TestController如下:
@RestControllerpublic class TestController {
@Autowired TestService testService;
@GetMapping("admin/product/lock") public Result testLock() { testService.incrWithLock(); return Result.ok(); }}public interface TestService {
void incrWithLock();}@Servicepublic class TestServiceImpl implements TestService {
@Autowired RedissonClient redissonClient;
@Override public synchronized void incrWithLock() { RBucket<Integer> bucket = redissonClient.getBucket("number"); // 获取key为number的value值 int number = bucket.get(); // 自增1 number++; // 在放回redis bucket.set(number); }}在测试之前,我们还要注意,需要使用redissonclient向redis中添加key为number的一个string类型的值,设置其值为0
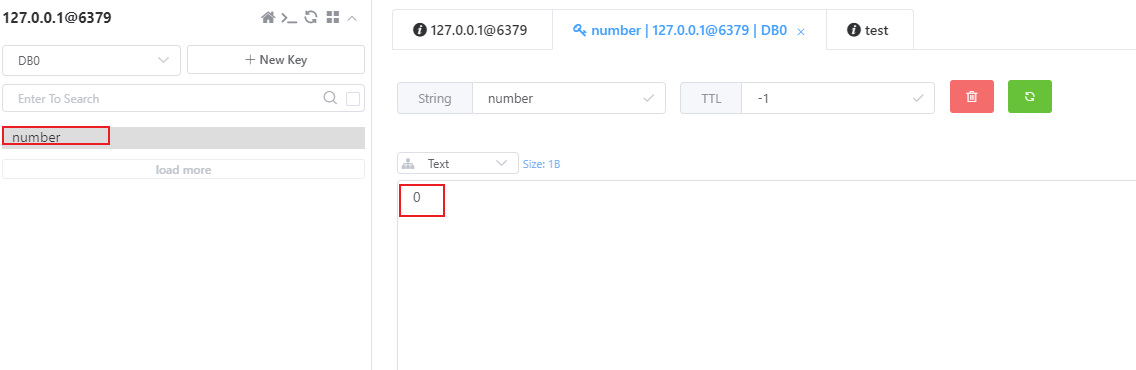
然后,我们就可以使用jmeter发起请求来测试了
启动多个服务实例
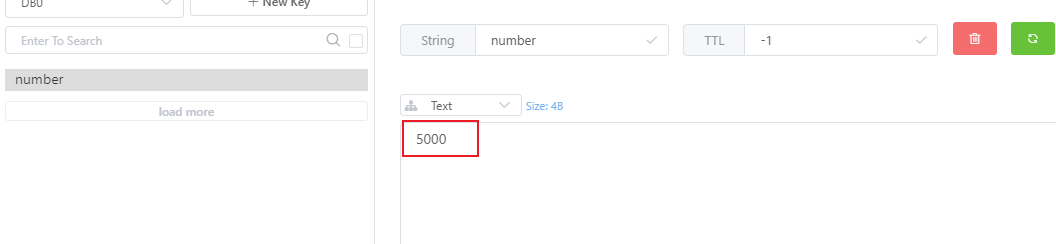
看起来结果是没有问题的,我们发了5000次请求,每一次给number的值自增1(初值为0),结果为5000。但是真的就没什么问题了吗?我们分别在8216,8226两个端口在启动两个商品服务,共三个商品服务继续测试。
首先,我们需要将配置中心中配置的商品服务端口号,注释掉
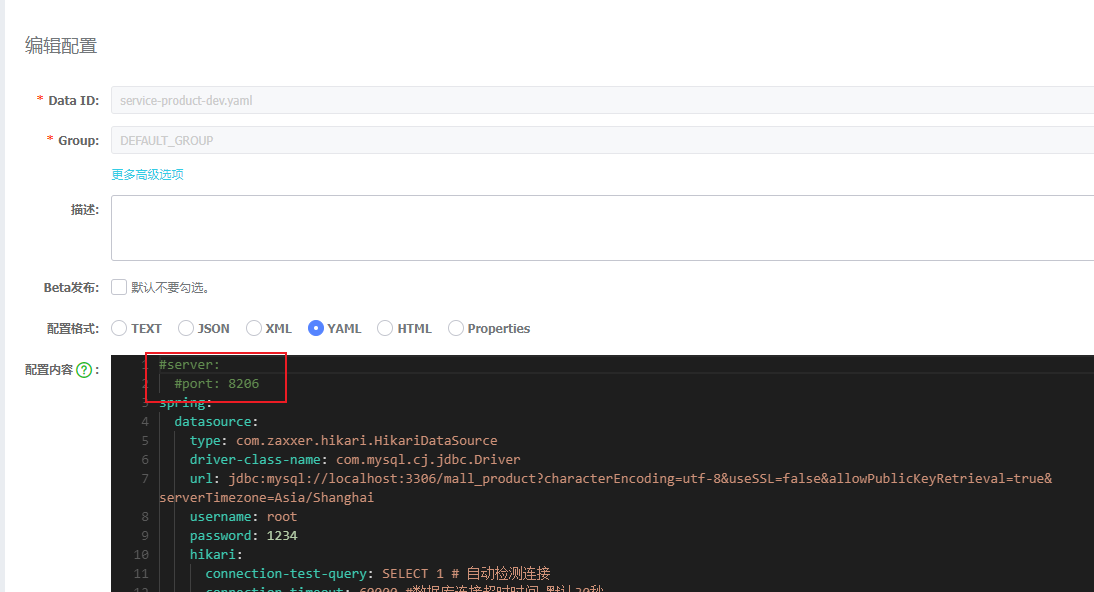
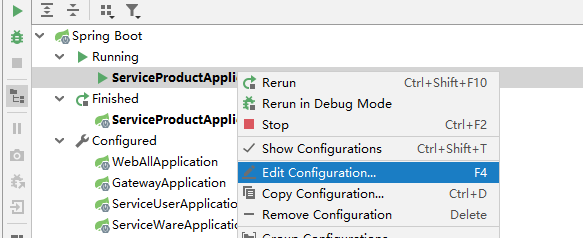
接着修改原来在8206端口启动的第一个商品服务的启动配置,增加server.port启动参数
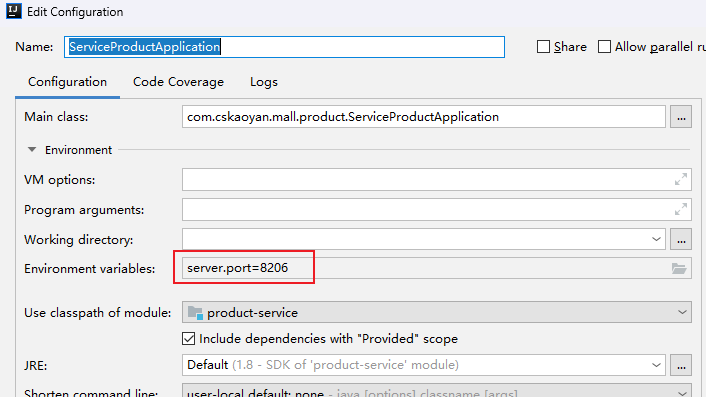
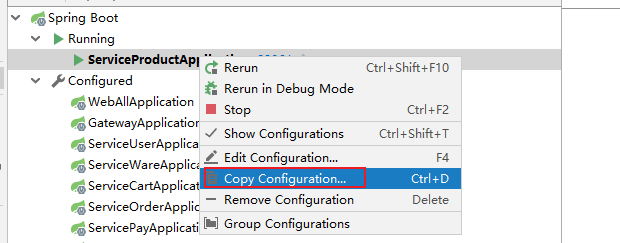
复制第一个商品服务的配置,增加server.port启动参数,让第二个服务的启动端口为8216
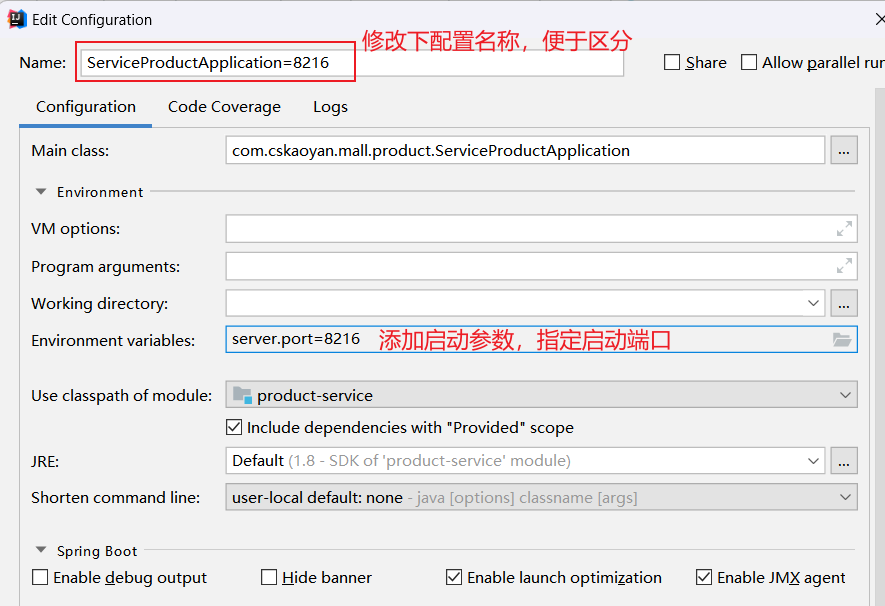
然后,可以在Rundashborad(高版本的IDEA中是services)中,运行这个启动配置,我们就启动了第二个商品服务
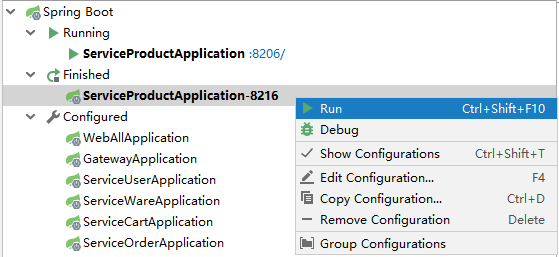
和启动第二个商品服务相同的步骤,我们可以启动第三个商品服务(启动端口8226),这里就不在截图了
测试多个服务实例
为了方便测试多个服务实例,我们还需要启动网关,通过网关将请求转发给商品服务集群。同时,我们还需要将redis中key为number的值改为0.
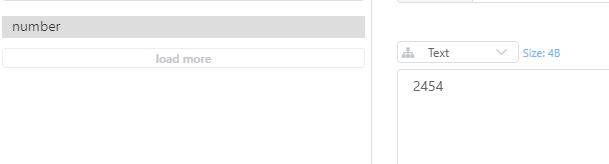
为什么当我们访问服务集群,结果就不正确了呢?
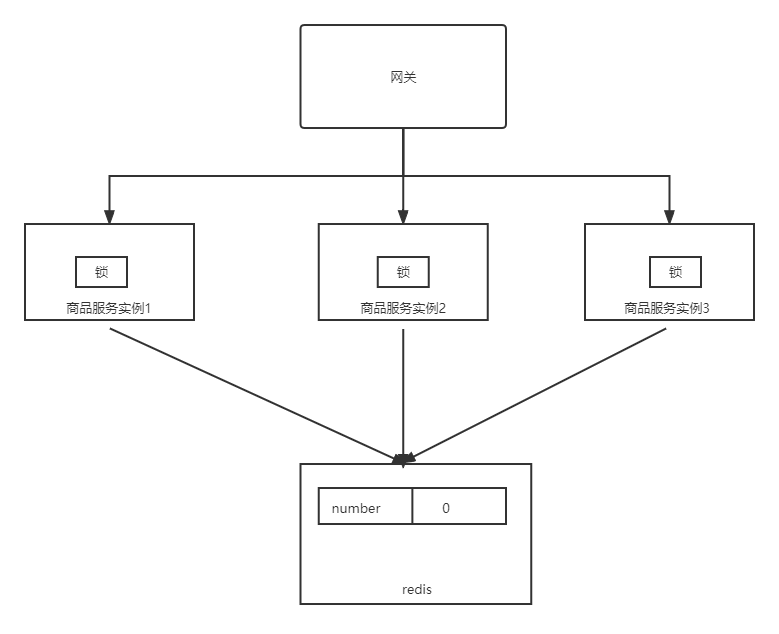
问题核心原因在于,多个服务实例中的线程,各用各的一把锁,访问共享数据时,没有实现并发请求的同步,所以导致了数据安全问题。
怎么解决这个问题呢?加锁的思路是没有问题的,但是问题的关键在于不应该加本地锁。我们应该让三个服务实例使用同一把锁,即这把锁不属于任何一个服务实例,而是独立于服务实例之外的一把锁,这把锁即分布式锁。
分布式锁
分布式锁不存在于Java服务实例进程,那么它可以存在于哪里呢?根据分布式锁的实现方式不同,它可以存在于
- MySQL中
- Redis中
- Zookeeper中
存在于不同的地方,就对应这不同的分布式锁的实现方式,我们最常使用的是基于Redis和基于Zookeeper的分布式锁实现方案,基于Redis实现的分布式锁性能最好,基于Zookeeper实现的分布式锁可靠性最好。在我们的项目中,我们就使用基于Redis实现的分布式锁。
基于SETNX实现
要实现一把锁,最主要是要模拟一把锁加锁和释放锁的状态。我们可以在Redis中定义一个string类型的值,把这个值的key当做是锁的名字,于是我们可以用是否有该key对应的值,当做是锁是否上锁的状态:
- key对应的value值存在,说明锁被上锁了,不能重复加锁
- key对应的value值不存在,说明锁还没有被上锁,可以加锁(就是在redis中添加该key对应的value值)
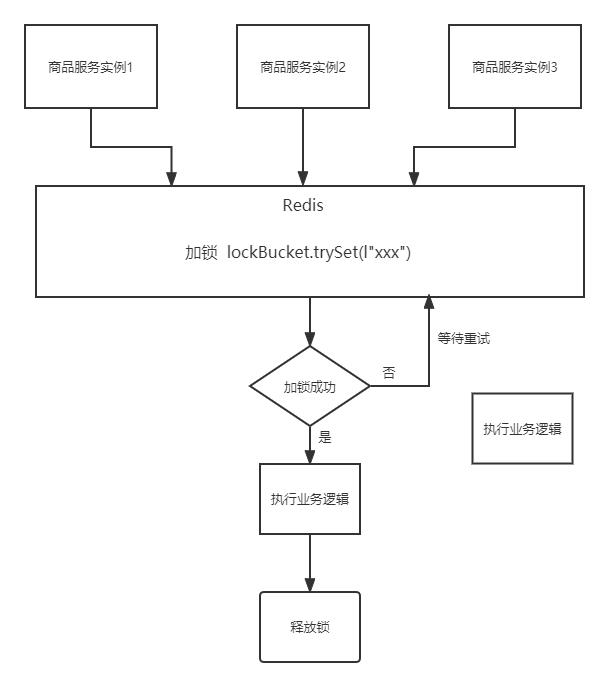
所以这样的加锁操作,刚刚好可以用SETNX来完成,所以可以改造我们的代码如下:
@Servicepublic class TestServiceImpl implements TestService {
@Autowired RedissonClient redissonClient;
@Override public void incrWithLock() { // 在操作Redis中的数据之前先加锁, lock:number 对应的值可以是任意的 RBucket<String> lockBucket = redissonClient.getBucket("lock:number"); // trySet方法等价于SETNX boolean exists = lockBucket.trySet("lockObj"); if (!exists) { // 如果锁已存在,即已经加锁, 则稍后重试 try { Thread.sleep(100); incrWithLock(); return; } catch (InterruptedException e) { e.printStackTrace(); } }
// 如果加锁成功,则自增key number对应的值 try { RBucket<Integer> bucket = redissonClient.getBucket("number"); // 获取key为number的value值 int number = bucket.get(); // 自增1 number++; // 在放回redis bucket.set(number); } finally { // 访问完数据之后,释放锁,即删除lock:number这个key lockBucket.delete(); }
}}
看起来,好像也没啥问题,但是这种实现方式有一个潜在的问题,就是如果在某一个商品服务实例中,加锁成功之后,因为某些原因,在还未释放锁之前,该实例挂了(java进程挂了),那就意味着这把锁永远不会被释放,那么其他服务实例就再也访问不到这把锁了。
增加过期时间
针对上述的可能存在的问题,我们可以增加一个解决方案就是,在利用SETNX加锁成功之后,给锁(给key)设置过期时间,这样一来,如果因为意外情况没有释放锁,到了锁的过期时间,其他服务实例,依然可以加锁成功。
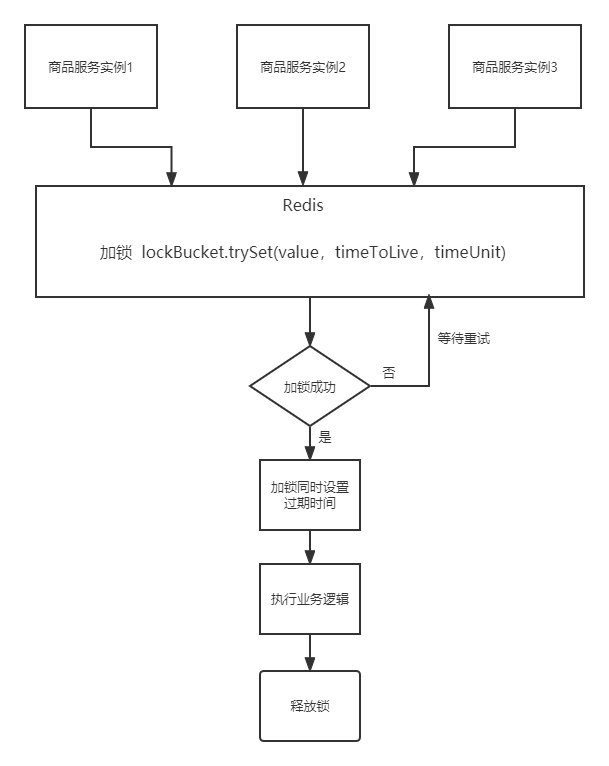
所以,结合过期时间,我们改造代码如下:
@Servicepublic class TestServiceImpl implements TestService {
@Autowired RedissonClient redissonClient;
@Override public void incrWithLock() { // 在操作Redis中的数据之前先加锁, lock:number 对应的值可以是任意的 RBucket<String> lockBucket = redissonClient.getBucket("lock:number"); // trySet方法等价于SETNX boolean exists = lockBucket.trySet("lockObj", 3, TimeUnit.SECONDS); if (!exists) { // 如果锁已存在,即已经加锁, 则稍后重试 try { Thread.sleep(100); incrWithLock(); return; } catch (InterruptedException e) { e.printStackTrace(); }
}
// 如果加锁成功 try { RBucket<Integer> bucket = redissonClient.getBucket("number"); // 获取key为number的value值 int number = bucket.get(); // 自增1 number++; // 在放回redis bucket.set(number); } finally { // 访问完数据之后,释放锁,即删除lock:number这个key lockBucket.delete(); }
}}以上代码如果测试是没问题的。但是这种实现方式,仍然有潜在的问题:
- 假设商品服务实例1先加锁成功,开始执行了,但是它执行4秒中,才会释放锁
- 但是过了3秒后,锁过期了,商品服务实例2加锁成功
- 又过了1s商品服务实例1执行完,释放锁,但是服务实例2还在执行,此时相当于没加锁
增加UUID防止误删
所以,为了防止锁被误删,所以在加锁的时候,我们给锁key对应的value,设置为一个uuid,并保存这个uuid。在释放锁的时候,如果获取到了锁,还要看看锁的value
- 如果锁key对应的value和释放锁的线程锁持有的uuid是不是同一个,说明是加锁线程在释放锁没有问题
- 但是如果不一致,说明加锁线程和释放锁的线程不是同一个,不能释放锁
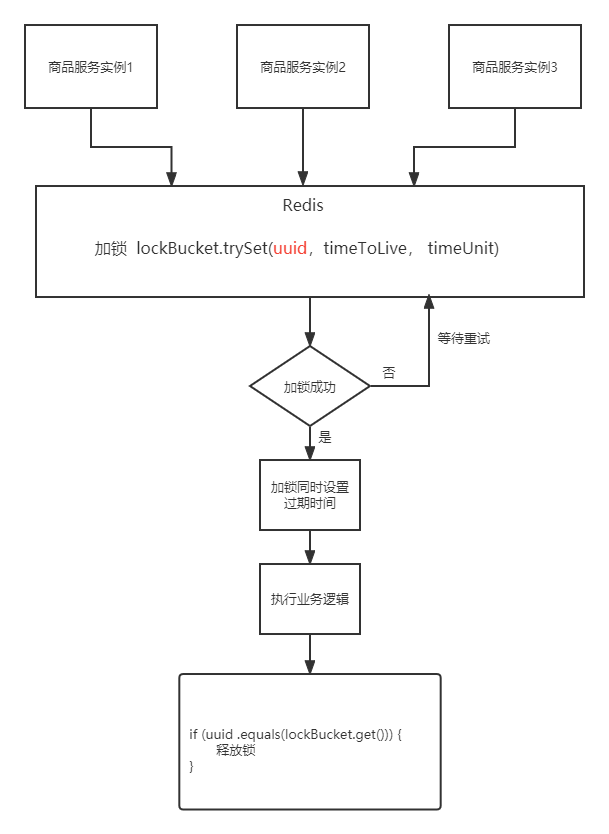
这样一来,就可以解决,锁的误删问题,代码如下
@Servicepublic class TestServiceImpl implements TestService {
@Autowired RedissonClient redissonClient;
@Override public void incrWithLock() { // 在操作Redis中的数据之前先加锁, lock:number 对应的值可以是任意的 RBucket<String> lockBucket = redissonClient.getBucket("lock:number"); String uuid = UUID.randomUUID().toString(); // trySet方法等价于SETNX,设置锁key对应的值 boolean exists = lockBucket.trySet(uuid, 3, TimeUnit.SECONDS); if (!exists) { // 如果锁已存在,即已经加锁, 则稍后重试 try { Thread.sleep(100); incrWithLock(); return; } catch (InterruptedException e) { e.printStackTrace(); }
}
// 如果加锁成功 try { RBucket<Integer> bucket = redissonClient.getBucket("number"); // 获取key为number的value值 int number = bucket.get(); // 自增1 number++; // 在放回redis bucket.set(number); } finally { // 不一定要在java代码里成为一个原子操作 if (uuid.equals(lockBucket.get())) { // 说明是加锁线程在释放锁,可以正确释放 lockBucket.delete(); }
}
}}但是增加uuid防止误删就完美了吗?当然不是,因为还是有可能会有问题:
- 假设商品服务实例1,先加锁,访问完Redis数据后,刚刚执行完uuid.equals(lockBucket.get())发现结果为true,准备释放锁了
- 但是在释放锁之前,刚好锁也过期了,商品服务实例2继续加锁成功
- 然后,商品服务实例1删除锁,测试商品服务实例2在访问Redis数据时相当于没有加锁
究其原因,就是因为判断和释放锁不是原子操作。
Redisson实现的分布式锁
所以,我们还需要让判断和释放锁成为原子操作,怎么样让它们成为原子操作呢?用Lua脚本来实现它们即可。因为Redis的工作线程是单线程,且Lua脚本可以直接在Redis中运行,所以一段Lua脚本中运行的必然是一个原子操作。而Redisson底层,就是利用Lua脚本来加锁和释放锁的。
如果使用Redisson,则代码如下:
@Servicepublic class TestServiceImpl implements TestService {
@Autowired RedissonClient redissonClient;
@Override public void incrWithLock() { // 获取锁 RLock redisLock = redissonClient.getLock("lock:number"); try { // 加锁,失败会在这里阻塞 redisLock.lock(); // 加锁成功,代码执行到这里 RBucket<Integer> bucket = redissonClient.getBucket("number"); // 获取key为number的value值 int number = bucket.get(); // 自增1 number++; // 在放回redis bucket.set(number); } finally { // 释放锁 redisLock.unlock(); }
}}为了确保分布式锁可用,我们要确保锁的实现同时满足以下四个条件:
- 互斥性。在任意时刻,只有一个客户端能持有锁。
- 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
- 解铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
- 加锁和解锁必须具有原子性
ReentranLock
而这四个条件,Redisson实现的分布式锁都可以满足,同时Redisson实现的分布式锁,还是可重入的。
分布式锁改造获取SKU信息
接下来,我们可以基于Redisson的分布式锁,改造getSkuInfo方法,主要基于两点:
- 增加缓存,将数据库中获取到的SKU信息放入缓存
- 当缓存中没有目标SKU信息时,加锁然后访问数据库,并将SKU信息放入缓存,最后释放锁
public SkuInfoDTO getSkuInfoWithRedisson(Long skuId) { // 定义key sku:skuId:info String skuInfoKey = RedisConst.SKUKEY_PREFIX + skuId + RedisConst.SKUKEY_SUFFIX; // 根据key获取redis中的SkuInfoDTO RBucket<SkuInfoDTO> bucket = redissonClient.getBucket(skuInfoKey); SkuInfoDTO skuInfoDTO = bucket.get(); if (skuInfoDTO != null) { // 如果获取到,则直接返回 return skuInfoDTO; }
// 定义锁对应的key String lockKey = RedisConst.SKUKEY_PREFIX + skuId + RedisConst.SKULOCK_SUFFIX; RLock redisLock = null; try { // 如果没有获取到,则获取锁 redisLock = redissonClient.getLock(lockKey); // 加锁 redisLock.lock();
// 这里是做double check,因为有可能别的服务已经将该SKU数据放入到Redis中 SkuInfoDTO retrySkuInfoDTO = bucket.get(); if (retrySkuInfoDTO != null) { // 说明别的服务已经将SKU信息放入Redis中,我们只需要从Redis中读取数据即可 return retrySkuInfoDTO; } /* 1. 说明缓存中还是没有 2. 而且,也没有其他服务将该SKU信息放入到Redis中,此时访问数据库 */ // 获取SKU基本信息 SkuInfo skuInfo = skuInfoMapper.selectById(skuId); // 根据skuId 查询图片列表集合 List<SkuImage> skuImageList = skuImageMapper.getSkuImages(skuId); skuInfo.setSkuImageList(skuImageList); SkuInfoDTO skuInfoFromDB = skuInfoConverter.skuInfoPO2DTO(skuInfo);
// 判断数据库中是否有该SKU if (skuInfoFromDB == null) { // 如果没有则在Redis中放入默认值,主要预防缓存穿透 skuInfoFromDB = new SkuInfoDTO(); }
bucket.set(skuInfoFromDB); return skuInfoFromDB;
} finally { if (redisLock != null) { // 释放锁 redisLock.unlock(); } }分布式锁+AOP
我们在前面说过,商品详情页时访问量比较大的,所以我们需要给整个商品详情页的数据增加缓存(除了商品价格这种实时数据)。因此我们不仅仅需要对获取SKU基本信息的getSkuInfo方法做改造,还需要对其他获取商品详情页数据的方法做改造。
但是,无论对于哪个方法做改造,改造的逻辑几乎都是一样的,即我们需要给多个方法做增强,增加一段通用处理逻辑,此时你会 想到什么呢?当然是AOP
既然要是用AOP,自然需要定义切面,但在定义切面之前,我们需要思考以下两个问题:
- 我们的切入点应该如何定义
- 我们应该使用什么样的通知类型
针对第一个问题,我们可以结合自定义注解,给需要增强的方法加自定义注解,所以我们的切入点使用@annotation注解找具有目标自定义注解的方法即可。
针对第二个问题,得根据我们的增强逻辑来决定,被增强的方法是访问数据库的,而我们的增强逻辑需要在访问数据库之前先访问缓存,如果缓存中没有,在被增强方法访问数据库之后,我们还需要将数据库中的查询结果,放入Redis,所以很显然,我们应该使用环绕通知。

所以我们可以定义自定义注解如下:
@Target({ElementType.METHOD})@Retention(RetentionPolicy.RUNTIME)public @interface RedisCache {
// 给缓存数据增加前缀,以区分不同的缓存数据 String prefix() default "cache:";
}定义切面如下:
@Component@Aspectpublic class RedisCacheAspect {
@Autowired private RedissonClient redissonClient;
// 定义一个环绕通知! @Around("@annotation(com.cskaoyan.mall.common.cache.RedisCache)") public Object gmallCacheAspectMethod(ProceedingJoinPoint point) { // 定义一个对象 Object obj = null; MethodSignature methodSignature = (MethodSignature) point.getSignature(); RedisCache redisCache = methodSignature.getMethod().getAnnotation(RedisCache.class); // 获取到注解上的前缀 String prefix = redisCache.prefix(); // 组成缓存的key! 获取方法传递的参数 String key = prefix + Arrays.asList(point.getArgs()).toString(); RLock lock = null; try { // 可以通过这个key 获取缓存的数据 obj = this.redissonClient.getBucket(key).get(); if (obj != null) { // 获取到了直接返回 return obj; } } catch (Exception e) { e.printStackTrace(); } try { // 加锁 lock = redissonClient.getLock(key + ":lock"); lock.lock(); Object redisData = this.redissonClient.getBucket(key).get(); // double check if (redisData != null) { // 获取到了直接返回 return redisData; }
// 执行业务逻辑:直接从数据库获取数据 obj = point.proceed(point.getArgs());
// 将结果放入redis obj = putInRedis(obj, key, methodSignature);
return obj;
} finally { // 解锁 if (lock != null) { lock.unlock(); } } }
/* 将数据放入Redis缓存 */ private Object putInRedis(Object obj, String key, MethodSignature methodSignature) { try { if (obj == null) { // 防止缓存穿透 //obj = new Object(); Class returnType = methodSignature.getReturnType(); if (returnType.isAssignableFrom(List.class)) { // 返回值是Collection或List类型 obj = new ArrayList(); } else if (Map.class.equals(returnType)) { // 返回值是Map类型 obj = new HashMap(); } else { // 其他类型 Constructor declaredConstructor = returnType.getDeclaredConstructor(); declaredConstructor.setAccessible(true); obj = declaredConstructor.newInstance(); } // 将缓存的数据变为 Json 的 字符串,默认值的过期时间是1分钟 this.redissonClient.getBucket(key).set(obj, RedisConst.SKUKEY_TEMPORARY_TIMEOUT, TimeUnit.SECONDS); } else { // 将缓存的数据变为 Json 的 字符串 this.redissonClient.getBucket(key).set(obj, RedisConst.SKUKEY_TIMEOUT, TimeUnit.SECONDS); } } catch (Exception e) { e.printStackTrace(); }
return obj; }
}定义好切面后,我们可以在获取详情页数据的时候使用了
@RedisCache(prefix = RedisConst.SKUKEY_PREFIX) @Override public SkuInfoDTO getSkuInfo(Long skuId) { ... }
@RedisCache(prefix = "spuSaleAttrListCheckBySku:") @Override public List<SpuSaleAttributeInfoDTO> getSpuSaleAttrListCheckBySku(Long skuId, Long spuId) { ... }
@Override @RedisCache(prefix = "skuValueIdsMap:") public Map<String, Long> getSkuValueIdsMap(Long spuId) { ... }
@Override @RedisCache(prefix = "categoryHierarchyByCategory3Id:") public CategoryHierarchyDTO getCategoryViewByCategoryId(Long category3Id) { ... }
@Override @RedisCache(prefix = "SpuPosterList:") public List<SpuPosterDTO> findSpuPosterBySpuId(Long spuId) { ... }
@RedisCache(prefix = "platformAttributeInfoList:") @Override public List<PlatformAttributeInfoDTO> getPlatformAttrInfoBySku(Long skuId) { ... }布隆过滤器BloomFilter
使用场景
缓存穿透问题,除了可以使用我们讲过的,在Redis中添加默认值并设置过期时间的方式之外,其实还有另外一种方式,就是使用布隆过滤器。
布隆过滤器有一个非常好的特征,就是能快速,可靠的帮助我们判断,某个值是否不存在于某个集合中。我们可以充分利用这一特征:
- 将所有在后台管理系统中添加的SKU商品的id放入到一个集合中(我们称之为所有SKU商品的skuId集合)
- 当处理获取SKU商品信息的请求时,我们可以取出请求中的skuId,然后利用布隆过滤器判断该skuId是否不在所有SKU商品的skuId集合,如果不在则直接返回
- 所以,当请求实际获取数据库中不存在的数据时,我们还是不会访问数据库,而是通过布隆过滤器拦截这样该请求
布隆过滤器及其构建过程
那么什么是布隆过滤器呢?布隆过滤器由一个长度为n的二进制数组,和k个hash函数组成。
要构造布隆过滤器,首先得有一个长度为n的二进制数组,每个存储单元的初值为0.

紧接着,我们需要在二进制数组中,标识目标集合中的每一个元素(向布隆过滤器中添加元素),这个过程就需要借助k个hash函数来完成了。对第m个hash函数
- 它会对标集合中的每个元素x做hash运算,将其映射到二进制数组中的位置i,并将第i个位置的元素值变为1
- 这个1表示第m个hash函数,在数组中的第i个位置,标记目标元素x存在于目标集合
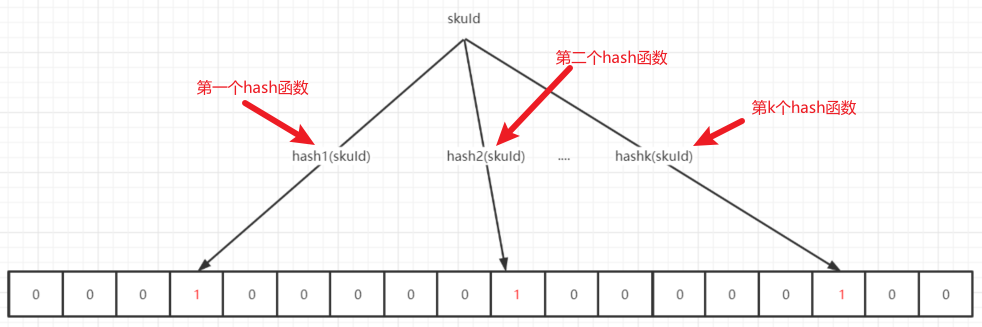
一旦k个hash函数,将目标数据集合中的所有元素映射完毕,那么布隆过滤器就构建好了。
那么布隆过滤器是如何判断元素是否存在于集合中的呢?看起来很简单,就是对待判断的元素继续根据k个hash函数做hash映射,如果k个hash函数所映射到的数组元素值是否都为1。
看似很简单,但其实不然:
- 即使对于一个待判断的元素,即使k个hash函数映射到的数组元素的值都是1,也不能说明这个元素在目标集合中是存在的。原因很简单,hash函数还存在hash冲突。
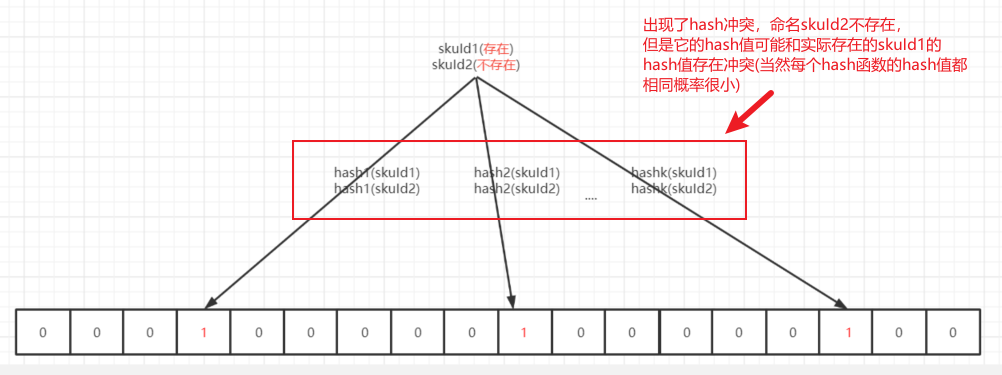
- 但是反过来,对于一个待判断元素,如果至少有一个hash函数映射到的数组元素为0即映射结果为不存在,那么就一定能说明,该元素在目标集合中不存在。
所以关于关于布隆顾虑器,我们还有以下结论:
- 使用布隆过滤器判断元素是否存在,是有误判率的。误判率p,二进制位数组长度m,hash函数个数k, 数据规模n(元素数量) 是有关系的,可以通过公式计算,已知数据规模,误判率,可以计算二进制数组长度, 以及hash函数的个数。
对于有n个元素的集合,保证误判率<=p的情况下,二进制数组长度的可以由如下公式求得
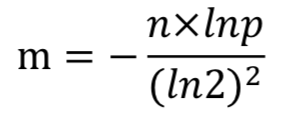
在已知二进制数组长度m和数据元素规模n的情况下,可以求得hash函数的个数k为
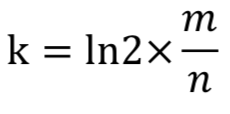
- 布隆过滤器中的元素是不能被删除的。所谓删除就是指,把二进制数组中该元素经过k个hash函数映射的元素值设置为0。这显然是不合理的,还是因为hash冲突的问题,有可能多个元素经过hash函数映射到同一个位置。如果在二进制数组中,将这个元素的值设置为0,把其他有hash冲突的元素也删除了。
但是布隆过滤器也有自己的优点:
- 由于布隆过滤器只需要一个二进制数组,占用的空间是比较小的
- 布隆过滤器的查询和插入的效率是很高的
- 数据安全性高,因为不存储任何目标集合中的原始数据
使用布隆过滤器
如果我们想要判断,一个skuId是否存在于数据库,我们只需要在构造布隆过滤器时,将目标集合变为数据库中所有的SKU商品的id集合即可。
Redisson本身对实现了基于Redis的布隆过滤器,可以非常方便的使用
// 根据指定名称(key)获取布隆过滤器 RBloomFilter rbloomFilter = redissonClient.getBloomFilter("xxx"); // 初始化布隆过滤器,预计统计元素数量为100000,期望误判率为0.01 rbloomFilter.tryInit(100000, 0.01);
// 向布隆过滤器中添加目标元素 rbloomFilter.add(目标元素);
// 判断目标元素是否存在,返回false表示不存在 boolen exists = rbloomFilter.contains(目标元素);在我们的商品服务中,我们需要在服务启动的时候就执行对于布隆过滤器的初始化(即仅仅需要执行一个操作),所以我们可以将布隆过滤器的初始化,可以使用CommandLineRunner接口
public interface CommandLineRunner {
/** 该方法会被SpringBoot在初始化完Spring容器之后自动调用 * Callback used to run the bean. * @param args incoming main method arguments * @throws Exception on error */ void run(String... args) throws Exception;
}所以我们可以这样使用
/* 这个BloomFilterRunner因为加了Component注解,所以会被放到Spring容器中, Spring容器初始化完毕后,该对象的run方法会被自动调用*/@Componentpublic class BloomFilterRunner implements CommandLineRunner {
@Autowired RedissonClient redissonClient;
@Override public void run(String... args) throws Exception { RBloomFilter<Long> rbloomFilter = redissonClient.getBloomFilter(RedisConst.SKU_BLOOM_FILTER); // 初始化布隆过滤器,预计统计元素数量为100000,期望误差率为0.01 rbloomFilter.tryInit(100000, 0.01); }}然后我们在上架SKU商品的时候,向布隆过滤器中添加元素
@Override public void onSale(Long skuId) {
/* ... */
//向添加布隆过滤器添加元素 RBloomFilter<Long> rbloomFilter = redissonClient.getBloomFilter(RedisConst.SKU_BLOOM_FILTER); rbloomFilter.add(skuId);
}在处理获取详情页商品信息的请求时,首先判断布隆过滤器中是否存在该元素,如果不存在,则直接返回默认值
@Override public ProductDetailDTO getItemBySkuId(Long skuId) {
ProductDetailDTO productDetailDTO = new ProductDetailDTO(); RBloomFilter<Long> bloomFilter = redissonClient.getBloomFilter(RedisConst.SKU_BLOOM_FILTER); if (!bloomFilter.contains(skuId)) { // 如果不存在,则返回默认值 return productDetailDTO; }
/* .... */ return productDetailDTO;}文章分享
如果这篇文章对你有帮助,欢迎分享给更多人!